URL(统一资源定位符, Uniform Resource Location)是URI(统一资源标识符, Uniform Resource Identifier)的一种,一般来讲,URL是Internet上用来描述信息资源的字符串,用于客户端访问www服务器或其它服务器的方式。来几个URL:
* ftp://host/filepath/
* http://
* ftp://表示通过文件传输协议FTP访问FTP服务器。
* telnet://表示通过远程登录协议Telnet进行远程登录。
* gopher://表示通过gopher协议访问Gopher服务器。
当然协议也可以自己扩展。
这个不扯太多,今天只讨论编码。
URL中包括中文
看代码,文件名编码-test.html放到tomcat(全局web.xml配置listings设置成true)下webapp目录下中的encoding目录下
<!DOCTYPE html>
<html>
<head>
<meat charset="utf-8"/>
</head>
<body>
<form>
<input name="q" value="编码test">
<input type="submit" value="submit"/>
</form>
</body>
</html>
浏览器(chrome,IE)访问该文件http://localhost:8080/encoding/
点击该文件:
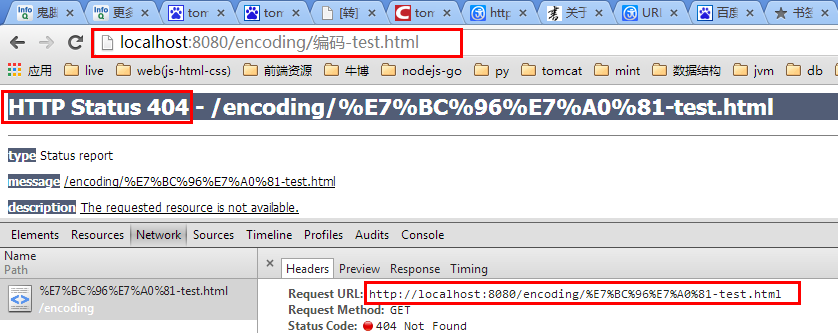
得出结论:在浏览器中输入带中文的URL,自动按utf-8编码转换(多了个%);404,说明服务器端没有正确的编码方式来处理该URL,导致找不到该文件。即浏览器与服务器端(tomcat)不是同一种编码格式来处理URL。幸好以前研究过部分tomcat的源代码,啥也不说,上图:(tomcat-7.0.42版本,CoyoteAdapter.java文件814行)
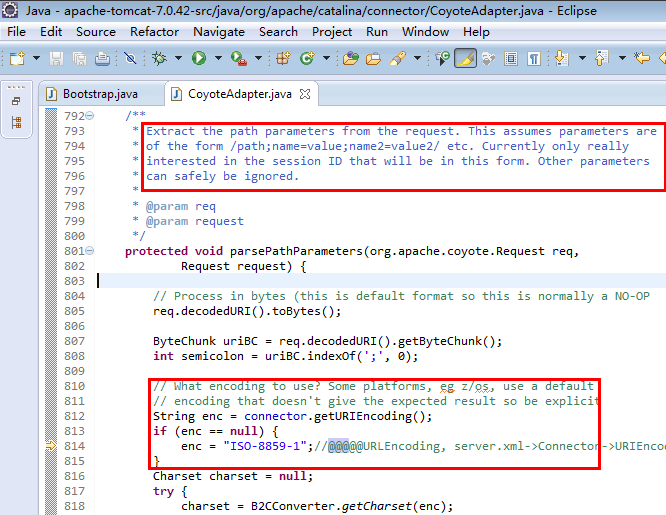
可以看到,tomcat默认是按US-ASCII编码方式来处理url,显然无法正确处理带中文的文件名。看其注释可知它是可配的,即在${tomcat_home}/conf/server.xml中Connector节点添加 URIEncoding="UTF-8",重起tomcat,再次访问,一切如我所愿。
form表单提交中的中文
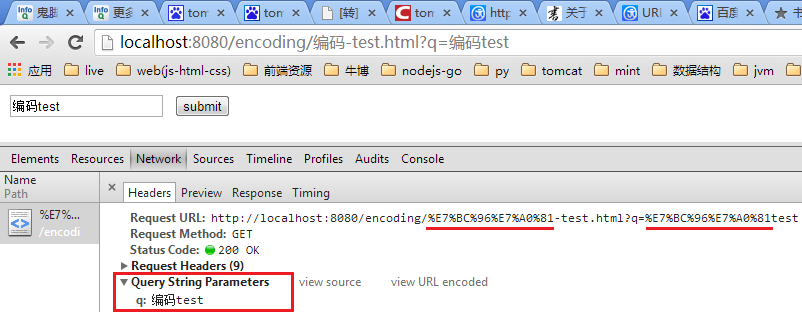
点击编码-test.html页面中的submit:
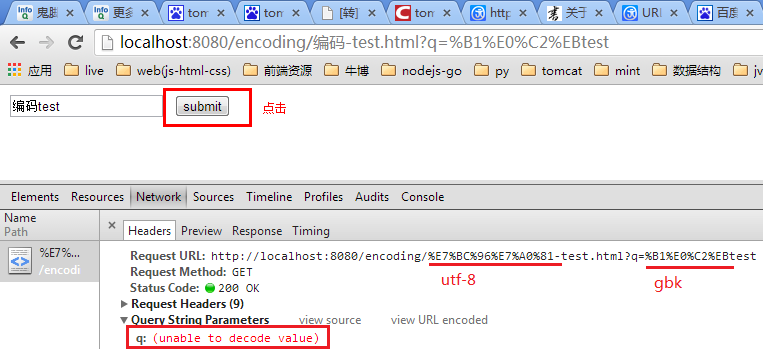
对于表单生成(GET)的URL查询字符中有中文,默认按操作系统的编码方式,试想这不乱套了吗,不同语言国家的浏览器访问同一页面,那么提交的数据会变的千奇百怪了吧。还好给表单加个配置accept-charset:
<form accept-charset="utf-8">
<input name="q" value="编码test">
<input type="submit" value="submit"/>
</form>
刷新页面,再次点击,一切都美好
Ajax的中文参数
首先不去实验一些浏览器的差异性了,因为你不可能不用ajax库,而自己包装XHR对象来实现。细节都被jQuery处理了,如果想了解细节,看jQuery的ajax部分代码。这里就给出一个参数配置contentType消息主体的内容类型后,添加该内容的字符集:
jQuery(form).ajaxSubmit({
url: "some url",
type: "post",
dataType: "json",
contentType: "application/x-www-form-urlencoded; charset=utf-8",
success: successFun
});
枯燥的定义
不想看又不可不看的部分
URL只允许使用US-ASCII字符集中的可打印字符(0x20-0x7e范围内的字符)。并且,由于其在URL方案或HTTP协议内具有特殊含义的字符(= %等),也不能使用,如:
保留字符
URL可以划分成若干个组件,协议、主机、路径等。有一些字符(:/?#[]@)是用作分隔不同组件的。例如:冒号用于分隔协议和主机,/用于分隔主机和路径,?用于分隔路径和查询参数,等等。还有一些字符(!$&'()*+,;=)用于在每个组件中起到分隔作用的,如=用于表示查询参数中的键值对,&符号用于分隔查询多个键值对。当组件中的普通数据包含这些特殊字符时,需要对其进行编码。
RFC3986中指定了以下字符为保留字符(如URL包括这些字符必须对其编码):
! * ' ( ) ; : @ & = + $ , / ? # [ ]
受限字符
还有一些字符,当他们直接放在Url中的时候,可能会引起解析程序的歧义。这些字符被视为不安全字符,原因有很多:
* 空格:URL在传输的过程,或者用户在排版的过程,或者文本处理程序在处理URL的过程,都有可能引入无关紧要的空格,或者将那些有意义的空格给去掉。
* 引号以及<>:引号和尖括号通常用于在普通文本中起到分隔Url的作用
* #:通常用于表示书签或者锚点
* %:百分号本身用作对不安全字符进行编码时使用的特殊字符,因此本身需要编码
* {}|\^[]`~:某一些网关或者传输代理会篡改这些字符
非ASCII字符集
中文、韩文......,统一utf-8编码格式。
小结
网络上传输的是二进制,URL编码,其实就是把字符映射成二进制的过程。RFC定义合法URL只能是可打印ASCII字符来表示,也包括一些表示特殊含义的保留字符和保留字符(文件名或路径中含有,则需转换成。如,=表示查询参数键值,需转换成%3D),这样才能保证服务端正确编码的解析。
一些常见的URL编码字符:
= 转换为 %3d
% 转换为 %25
空格 转换为 %20
新行 转换为 %0a
空字符 转换为 %00
详细参见HTML URL Encoding Reference
最后的js中的三个方法
escape(unescape),encodeURI(decodeURI),encodeURIComponent(decodeURIComponent)---都是用于将不安全不合法的URL字符转换为合法的URL字符表示,不同点如下:
安全字符不同
不会对以下字符进行编码
* escape(69个):*/@+-._0-9a-zA-Z
* encodeURI(82个):!#$&'()*+,/:;=?@-._~0-9a-zA-Z
* encodeURIComponent(71个):!'()*-._~0-9a-zA-Z
兼容性不同
escape函数是从Javascript 1.0的时候就存在了,它返回的是unicode,其他两个函数是在Javascript 1.5才引入的。但是由于Javascript 1.5已经非常普及了,所以实际上使用encodeURI和encodeURIComponent并不会有什么兼容性问题。
对Unicode字符的编码方式不同
这三个函数对于ASCII字符的编码方式相同,均是使用百分号+两位十六进制字符来表示。但是对于Unicode字符,escape的编码方式是%uxxxx,其中的xxxx是用来表示unicode字符的4位十六进制字符。这种方式已经被W3C废弃了。但是在ECMA-262标准中仍然保留着escape的这种编码语法。encodeURI和encodeURIComponent则使用UTF-8对非ASCII字符进行编码,然后再进行百分号编码。这是RFC推荐的。
因此建议尽可能的使用encodeURI和encodeURIComponent这两个函数替代escape进行编码。
适用场合不同
encodeURI被用作对一个完整的URI进行编码,而encodeURIComponent被用作对URI的一个组件进行编码。从上面提到的安全字符范围表格来看,我们会发现,encodeURIComponent编码的字符范围要比encodeURI的大。我们上面提到过,保留字符一般是用来分隔URI组件(一个URI可以被切割成多个组件,参考预备知识一节)或者子组件(如URI中查询参数的分隔符),如:号用于分隔scheme和主机,?号用于分隔主机和路径。由于encodeURI操纵的对象是一个完整的的URI,这些字符在URI中本来就有特殊用途,因此这些保留字符不会被encodeURI编码,否则意义就变了。
组件内部有自己的数据表示格式,但是这些数据内部不能包含有分隔组件的保留字符,否则就会导致整个URI中组件的分隔混乱。因此对于单个组件使用encodeURIComponent,需要编码的字符就更多了。
保留及受限字符
- % 保留作为编码字符的转义标志
- / 保留作为路径组件中分隔路径段的定界符
- . 保留在路径组件中使用
- .. 保留在路径组件中使用
-
保留作为分段定界符使用
- ? 保留作为查询字符串定界符使用
- ; 保留作为参数定界符使用
- : 保留作为方案、用户/口令,以及主机/端口组件的定界符使用
- $ , + 保留
- @ & = 在某些方案的上下文中有特殊的含义,保留
- { } | \ ^ ~ [ ] ` 由于各种Agent代理,比如各种网关的不安全处理,受限
- < > " 不安全;这些字符在URL范围外通常有意义的,如在文档中对URL自身进行定界
- 0x00–0x1F, 0x7F 受限,这些十六进制范围内控字符都在US-ASCII字符集中不可打印区
-
0x7F 受限,十六进制范围内控字符都在US-ASCII字符集中不在7比特范围内
参拷